BlueStore存储介绍
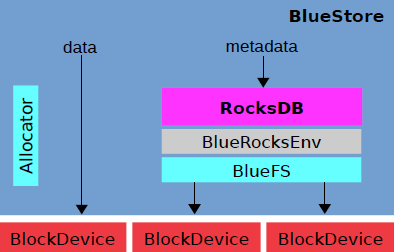
Bluestore 建立在块设备之上,采用rocksdb作为元数据存储,数据直接在块设备上写入,bluestore自己实现了委派规则(allocation code,to allocate which block-device shall be written);关键点(key-challenge):块设备需要与rocksdb共享,包括持久化数据、日志等需要写入块设备中,自此实现自制的rocksdb,并实现了最简化的文件系统bluefs用来做元数据的基本读写操作,并与bluestore共享块设备信息。
Bluestore= block(device) + NewStore
bluestore的诞生是为了解决filestore自身维护一套journal并同时还需要基于系统文件系统的写放大问题,并且filestore本身没有对SSD进行优化,因此bluestore相比于filestore主要做了两方面的核心工作:
- 去掉journal,直接管理裸设备
- 针对SSD进行单独优化
BlueStore的整体架构如下图所示:
BlueStore元数据
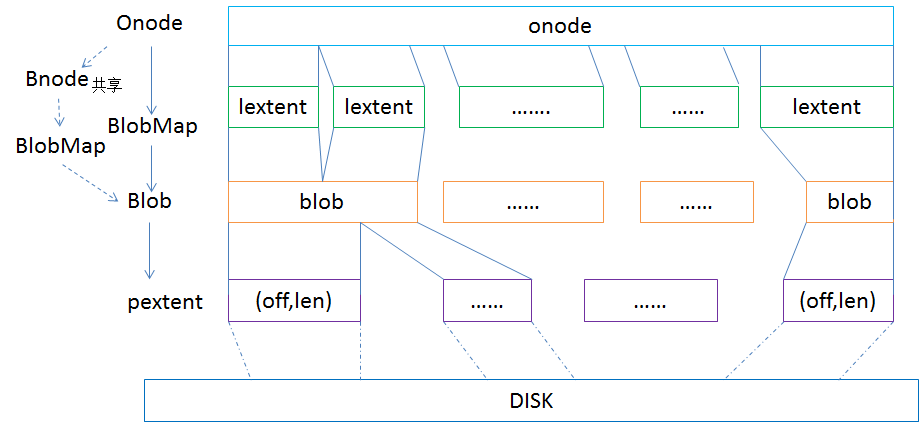
在存储引擎filestore里,对象的表现形式是对应到文件系统里的文件,默认4MB大小的文件,但是在bluestore里,已经没有传统的文件系统,而是自己管理裸盘,因此需要有元数据来管理对象,对应的就是Onode,Onode是常驻内存的数据结构,持久化的时候会以kv的形式存到rocksdb里。
在onode里又分为lextent,表示逻辑的数据块,用一个map来记录,一个onode里会存在多个lextent,lextent通过blob的id对应到blob(bluestore_blob_t ),blob里通过pextent对应到实际物理盘上的区域(pextent里就是offset和length来定位物理盘的位置区域)。一个onode里的多个lextent可能在同一个blob里,而一个blob也可能对应到多个pextent。
另外还有Bnode这个元数据,它是用来表示多个object可能共享extent,目前在做了快照后写I/O触发的cow进行clone的时候会用到。
环境:
OS:Centos 7.5.1804
内核版本:3.10.0-862.14.4.el7.x86_64
Ceph版本:luminous 12.2.8(当前最新稳定版)
192.168.3.81 ceph-kub-81 mon,mgr,mds
192.168.3.82 ceph-kub-82 mon,mgr,mds
192.168.3.83 ceph-kub-83 mon,osd
192.168.3.84 ceph-kub-84 osd
192.168.3.85 ceph-kub-85 osd
osd节点:每台磁盘分区sdb,sdc(sdb 分3个区存储wal,db,osd,最好用SSD硬盘)
修改HOST解析
vi /etc/hosts
192.168.3.81 ceph-kub-81
192.168.3.82 ceph-kub-82
192.168.3.83 ceph-kub-83
192.168.3.84 ceph-kub-84
192.168.3.85 ceph-kub-85
安装ntp
yum installl ntp
启动ntp服务
systemctl restart ntpd.service systemctl enable ntpd.service
修改sudoers
sudo visudo
找到
Defaults requiretty
选项直接注释掉
在所有节点创建用户(每个节点都创建ceph用户)
useradd ceph
授权ceph权限
vi /etc/sudoers
ceph ALL=(ALL) NOPASSWD: ALL
管理节点执行
切换用户
su ceph
生成秘钥,免密码登陆
ssh-keygen ssh-copy-id ceph@ceph-kub-81 ssh-copy-id ceph@ceph-kub-82 ssh-copy-id ceph@ceph-kub-83 ssh-copy-id ceph@ceph-kub-84 ssh-copy-id ceph@ceph-kub-85
安装ceph-deploy
sudo yum install ceph-deploy
修改ceph-deploy配置工具(修改替换ceph官方源,走官方源除非有翻墙,不然执行这个)
vi /usr/lib/python2.7/site-packages/ceph_deploy/hosts/centos/install.py
...
def install(distro, version_kind, version, adjust_repos, **kw):
packages = map_components(
NON_SPLIT_PACKAGES,
kw.pop('components', [])
)
gpgcheck = kw.pop('gpgcheck', 1)
adjust_repos = False ###新增这条###
logger = distro.conn.logger
machine = distro.machine_type
repo_part = repository_url_part(distro)
dist = rpm_dist(distro)
distro.packager.clean()
...
创建目录
mkdir ceph-cluster chown -R ceph:ceph ceph-cluster chmod -R 755 ceph-cluster
添加Ceph repo源
vi /etc/yum.repos.d/ceph.repo
[ceph] name=ceph baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/x86_64/ gpgcheck=0 priority=1 [ceph-noarch] name=cephnoarch baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/noarch/ gpgcheck=0 priority=1 [ceph-source] name=Ceph source packages baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/SRPMS gpgcheck=0 priority=1
关闭防火墙或者在防火墙开放对应端口
vi /etc/sysconfig/iptables
*filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [0:0] -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT -A INPUT -p icmp -j ACCEPT -A INPUT -i lo -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 6789 -j ACCEPT ##新增## -A INPUT -p tcp -m state --state NEW -m tcp --dport 6800:7300 -j ACCEPT ##新增## -A INPUT -p tcp -m state --state NEW -m tcp --dport 7480 -j ACCEPT ##新增## -A INPUT -p tcp -m state --state NEW -m tcp --dport 7000 -j ACCEPT ##新增## -A INPUT -j REJECT --reject-with icmp-host-prohibited -A FORWARD -j REJECT --reject-with icmp-host-prohibited COMMIT
重启iptables服务
sudo service iptables restart
创建monitor节点,所有节点安装ceph
ceph-deploy new ceph-kub-81 ceph-kub-82 ceph-kub-83 ceph-deploy install --release luminous ceph-kub-81 ceph-kub-82 ceph-kub-83 ceph-kub-84 ceph-kub-85
初始化mon
ceph-deploy mon create-initial
配置admin key 到每个节点
ceph-deploy admin ceph-kub-81 ceph-kub-82 ceph-kub-83 ceph-kub-84 ceph-kub-85
创建管理daemon节点
[ceph@ceph-kub-81 ceph-cluster]$ ceph-deploy mgr create ceph-kub-81 ceph-kub-82
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/ceph/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy mgr create ceph-kub-81 ceph-kub-82
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] mgr : [('ceph-kub-81', 'ceph-kub-81'), ('ceph-kub-82', 'ceph-kub-82')]
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f26bd1ab638>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func : <function mgr at 0x7f26bda0d0c8>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.mgr][DEBUG ] Deploying mgr, cluster ceph hosts ceph-kub-81:ceph-kub-81 ceph-kub-82:ceph-kub-82
创建MGR节点
ceph-deploy mgr create ceph-kub-81 ceph-kub-82
登陆到每个OSD节点,使用ceph-volume lvm来管理磁盘,block.db,block.wal建议存放在SSD硬盘介质上(我们这里sdb是SSD硬盘)
LVM创建磁盘
pvcreate /dev/sdb vgcreate ceph-pool /dev/sdb lvcreate -n osd0.wal -L 10G ceph-pool lvcreate -n osd0.db -L 10G ceph-pool lvcreate -n osd0 -l 100%FREE ceph-pool
pvcreate /dev/sdc vgcreate osd-pool /dev/sdc lvcreate -n osd1 -l 100%FREE osd-pool
创建OSD
管理节点执行:
ceph-deploy --overwrite-conf osd create ceph-node-43 --data ceph-pool/osd0 --block-db ceph-pool/osd0.db --block-wal ceph-pool/osd0.wal --bluestore ceph-deploy --overwrite-conf osd create ceph-node-44 --data ceph-pool/osd0 --block-db ceph-pool/osd0.db --block-wal ceph-pool/osd0.wal --bluestore ceph-deploy --overwrite-conf osd create ceph-node-44 --data ceph-pool/osd0 --block-db ceph-pool/osd0.db --block-wal ceph-pool/osd0.wal --bluestore ceph-deploy --overwrite-conf osd create ceph-node-43 --data osd-pool/osd1 --block-db ceph-pool/osd0.db --block-wal ceph-pool/osd0.wal --bluestore ceph-deploy --overwrite-conf osd create ceph-node-44 --data osd-pool/osd1 --block-db ceph-pool/osd0.db --block-wal ceph-pool/osd0.wal --bluestore ceph-deploy --overwrite-conf osd create ceph-node-44 --data osd-pool/osd1 --block-db ceph-pool/osd0.db --block-wal ceph-pool/osd0.wal --bluestore
查看状态
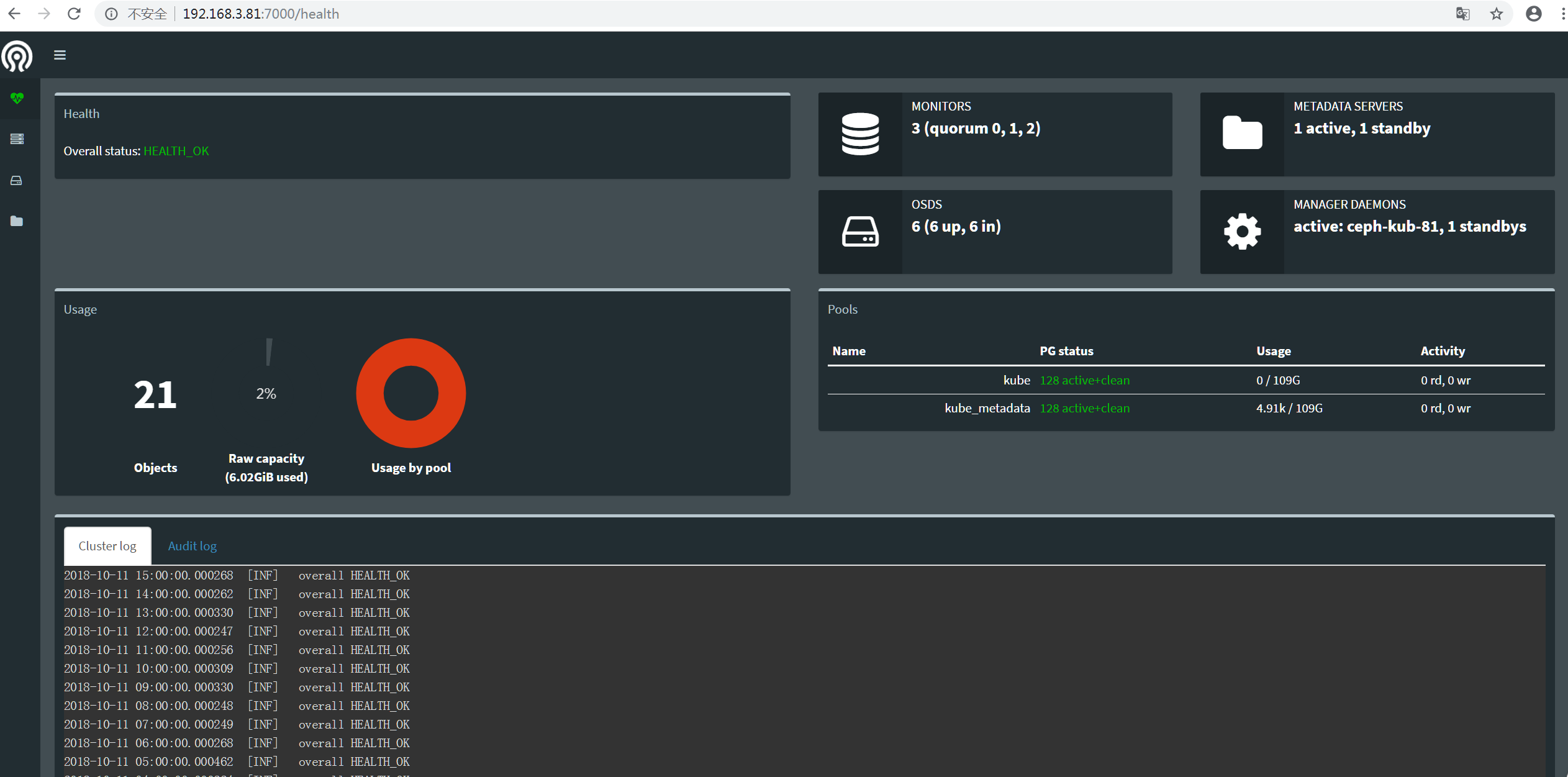
[ceph@ceph-kub-81 root]$ sudo ceph -s
cluster:
id: d5de5c6d-50d9-4ea6-9c0f-3a83b49f13dc
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-kub-81,ceph-kub-82,ceph-kub-83
mgr: ceph-kub-81(active), standbys: ceph-kub-82
mds: kube_cephfs-1/1/1 up {0=ceph-kub-81=up:active}, 1 up:standby
osd: 6 osds: 6 up, 6 in
data:
pools: 2 pools, 256 pgs
objects: 21 objects, 4.80KiB
usage: 6.03GiB used, 324GiB / 330GiB avail
pgs: 256 active+clean
[ceph@ceph-kub-81 root]$ sudo ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.32217 root default -3 0.10739 host ceph-kub-83 0 hdd 0.05859 osd.0 up 1.00000 1.00000 3 hdd 0.04880 osd.3 up 1.00000 1.00000 -5 0.10739 host ceph-kub-84 1 hdd 0.05859 osd.1 up 1.00000 1.00000 4 hdd 0.04880 osd.4 up 1.00000 1.00000 -7 0.10739 host ceph-kub-85 2 hdd 0.05859 osd.2 up 1.00000 1.00000 5 hdd 0.04880 osd.5 up 1.00000 1.00000
配置dashboard
在mgr节点上执行:
ceph config-key put mgr/dashboard/server_addr 0.0.0.0(这条可以先不执行) ceph config-key put mgr/dashboard/server_port 7000 sudo ceph mgr module enable dashboard
访问dashboard
http://192.168.3.81:7000
CephFs 创建
- 当前一套集群只能有一个文件系统存在。
- 一个 Ceph 文件系统需要至少两个 RADOS 存储池,一个用于数据、一个用于元数据。配置这些存储池时需考虑:
为元数据存储池设置较高的副本水平,因为此存储池丢失任何数据都会导致整个文件系统失效。
为元数据存储池分配低延时存储器(像 SSD ),因为它会直接影响到客户端的操作延时。
创建mds
ceph-deploy mds create ceph-kub-81 ceph-kub-82
创建存储池
sudo ceph osd pool create kube 128 sudo ceph osd pool create kube_metadata 128
确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值:
- 少于 5 个 OSD 时可把 pg_num 设置为 128
- OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512
- OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096
- OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
- 自己计算 pg_num 取值时可借助 pgcalc 工具
随着 OSD 数量的增加,正确的 pg_num 取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。
创建文件系统
sudo ceph fs new kube_cephfs kube_metadata kube
查看信息
[ceph@ceph-kub-81 root]$ sudo ceph fs ls name: kube_cephfs, metadata pool: kube_metadata, data pools: [kube ]
其他常用服务启动命令列举一些
systemctl start ceph-mon@ceph-node-43
systemctl start ceph-mgr@ceph-node-41
systemctl start ceph-mds@ceph-kub-82
systemctl start ceph-osd@1
systemctl start ceph-osd@5


最新评论